Introduction
Boost.Bloom provides the class template boost::bloom::filter
that can be configured to implement a classical Bloom filter as well as
variations discussed in the literature such as block filters, multiblock filters,
and more.
#include <boost/bloom.hpp>
#include <cassert>
#include <iostream>
#include <string>
int main()
{
// Bloom filter of strings with 5 bits set per insertion
using filter = boost::bloom::filter<std::string, 5>;
// create filter with a capacity of 1'000'000 bits
filter f(1'000'000);
// insert elements (they can't be erased, Bloom filters are insert-only)
f.insert("hello");
f.insert("Boost");
// elements inserted are always correctly checked as such
assert(f.may_contain("hello") == true);
// elements not inserted may incorrectly be identified as such with a
// false positive rate (FPR) which is a function of the array capacity,
// the number of bits set per element and generally how the boost::bloom::filter
// was specified
if(f.may_contain("bye")) { // likely false
std::cout << "false positive\n";
}
else {
std::cout << "everything worked as expected\n";
}
}The different filter variations supported are specified at compile time
as part of the boost::bloom::filter instantiation definition.
Boost.Bloom has been implemented with a focus on performance;
SIMD technologies such as AVX2, Neon and SSE2 can be leveraged to speed up
operations.
Getting Started
Consult the website section on how to install the entire Boost project or only Boost.Bloom and its dependencies.
Boost.Bloom is a header-only library, so no additional build phase is needed. C++11 or later required. The library has been verified to work with GCC 4.8, Clang 3.9 and Visual Studio 2015 (and later versions of those). You can check that your environment is correctly set up by compiling the example program shown above.
Bloom Filter Primer
A Bloom filter (named after its inventor Burton Howard Bloom) is a probabilistic data structure where inserted elements can be looked up with 100% accuracy, whereas looking up for a non-inserted element may fail with some probability called the filter’s false positive rate or FPR. The tradeoff here is that Bloom filters occupy much less space than traditional non-probabilistic containers (typically, around 8-20 bits per element) for an acceptably low FPR. The greater the filter’s capacity (its size in bits), the lower the resulting FPR.
In general, Bloom filters are useful to prevent/mitigate queries against large data sets when exact retrieval is costly and/or can’t be made in main memory.
Example: Speeding up unsuccessful requests to a database
One prime application of Bloom filters and similar data structures is for the prevention of expensive disk/network accesses when these would fail to retrieve a given piece of information. For instance, suppose we are developing a frontend for a database with access time 10 ms and we know 50% of the requests will not succeed (the record does not exist). Inserting a Bloom filter with a lookup time of 200 ns and a FPR of 0.5% will reduce the average response time of the system from 10 ms to
(10 + 0.0002) × 50.25% + 0.0002 × 49.75% ≅ 5.03 ms,
that is, we get a ×1.99 overall speedup. If the database holds 1 billion records, an in-memory filter with say 8 bits per element will occupy 0.93 GB, which is perfectly realizable.
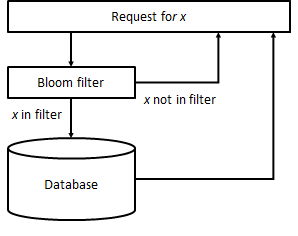
Applications have been described in the areas of web caching, dictionary compression, network routing and genomics, among others. Broder and Mitzenmacher provide a rather extensive review of use cases with a focus on networking.
Implementation
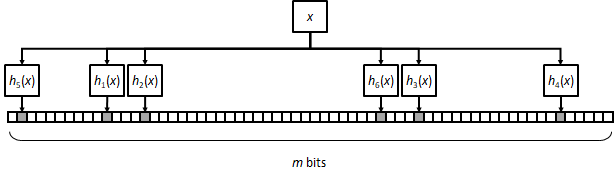
The implementation of a classical Bloom filter consists of an array of m bits, initially set to zero. Inserting an element x reduces to selecting k positions pseudorandomly (with the help of k independent hash functions) and setting them to one.
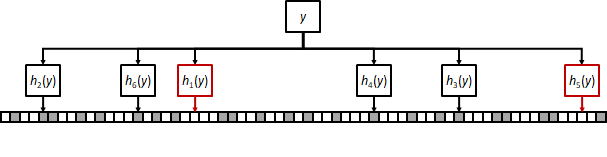
To check if an element y is in the filter, we follow the same procedure and see if the selected bits are all set to one. In the example figure there are two unset bits, which definitely indicates y was not inserted in the filter.
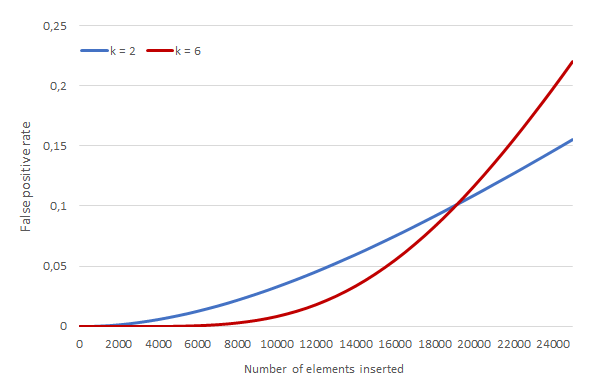
A false positive occurs when the bits checked happen to be all set to one due to other, unrelated insertions. The probability of having a false positive increases as we add more elements to the filter, whereas for a given number n of inserted elements, a filter with greater capacity (larger bit array) will have a lower FPR. The number k of bits set per operation also affects the FPR, albeit in a more complicated way: when the array is sparsely populated, a higher value of k improves (decreases) the FPR, as there are more chances that we hit a non-set bit; however, if k is very high the array will have more and more bits set to one as new elements are inserted, which eventually will reach a point where we lose out to a filter with a lower k and thus a smaller proportion of set bits. For given values of n and m, the optimum k is \(\lfloor k_{\text{opt}}\rfloor\) or \(\lceil k_{\text{opt}}\rceil\), with
\(k_{\text{opt}}=\displaystyle\frac{m\cdot\ln2}{n},\)
for a minimum FPR close to \(1/2^{k_{\text{opt}}} \approx 0.6185^{m/n}\). See the appendix on FPR estimation for more details.
Variations on the Classical Filter
Block Filters
An operation on a Bloom filter involves accessing k different positions in memory, which, for large arrays, results in k CPU cache misses and affects the operation’s performance. A variation on the classical approach called a block filter seeks to minimize cache misses by concentrating all bit setting/checking in a small block of b bits pseudorandomly selected from the entire array. If the block is small enough, it will fit in a CPU cacheline, thus drastically reducing the number of cache misses.
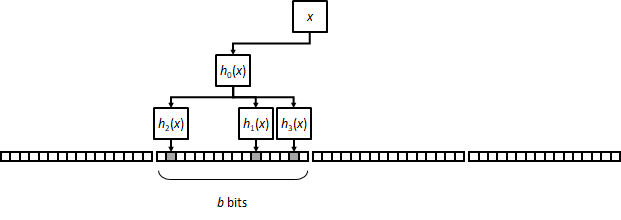
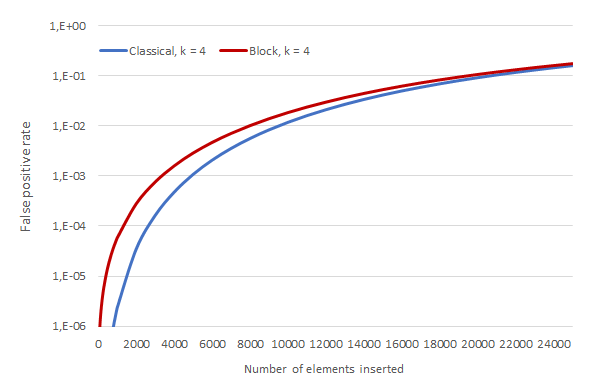
The downside is that the resulting FPR is worse than that of a classical filter for the same values of n, m and k. Intuitively, block filters reduce the uniformity of the distribution of bits in the array, which ultimately hurts their probabilistic performance.
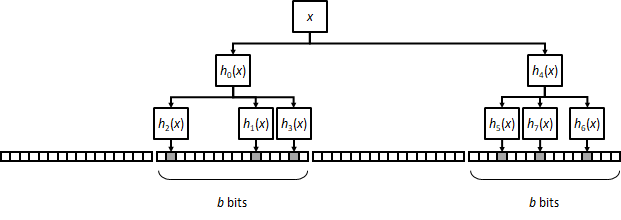
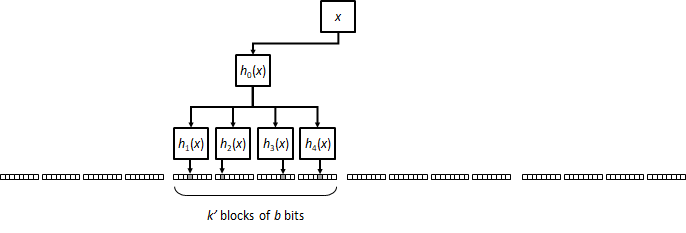
A further variation in this idea is to have operations select k blocks with k' bits set on each. This, again, will have a worse FPR than a classical filter with k·k' bits per operation, but improves on a plain k·k' block filter.
Multiblock Filters
Multiblock filters take block filters' approach further by having bit setting/checking done on a sequence of consecutive blocks of size b, so that each block takes exactly one bit. This still maintains a good cache locality but improves FPR with respect to block filters because bits set to one are more spread out across the array.
Multiblock filters can also be combined with multi-insertion. In general, for the same number of bits per operation and equal values of n and m, a classical Bloom filter will have the better (lower) FPR, followed by multiblock filters and then block filters. Execution speed will roughly go in the reverse order. When considering block/multiblock filters with multi-insertion, the number of available configurations grows quickly and you will need to do some experimenting to locate your preferred point in the (FPR, capacity, speed) tradeoff space.
Tutorial
A boost::bloom::filter can be regarded as a bit array divided into subarrays that
are selected pseudo-randomly (based on a hash function) upon insertion:
each of the subarrays is passed to a subfilter that marks several of its bits according
to some associated strategy.
Note that although boost::bloom::filter mimics the interface of a container
and provides operations such as insert, it is actually not a
container: for instance, insertion does not involve the actual storage
of the element in the data stucture, but merely sets some bits in the internal
array based on the hash value of the element.
Filter Definition
template< typename T, std::size_t K, typename Subfilter = block<unsigned char, 1>, std::size_t Stride = 0, typename Hash = boost::hash<T>, typename Allocator = std::allocator<unsigned char> > class filter;
Subfilter
A subfilter defines the local strategy for setting or checking bits within a selected subarray of the bit array. It determines how many bits are modified per operation, how they are arranged in memory, and how memory is accessed. The following subfilters are provided:
| Subfilter | Description | Pros | Cons |
|---|---|---|---|
|
Sets |
Very fast access time |
FPR is worse (higher) the smaller |
|
Sets one bit in each of the elements of a |
Better (lower) FPR than |
Performance may worsen if cacheline boundaries are crossed when accessing the subarray |
|
Statistically equivalent to |
Always prefer it to |
FPR is worse (higher) than |
|
Statistically equivalent to |
Always prefer it to |
Slower than |
In the table above, Block can be an unsigned integral type
(e.g. unsigned char, uint32_t, uint64_t), or
an array of 2N unsigned integrals (e.g. uint64_t[8]). In general,
the wider Block is, the better (lower) the resulting FPR, but
cache locality worsens and performance may suffer as a result.
Note that the total number of bits set/checked for a
boost::bloom::filter<T, K, subfilter<…, K'>> is K * K'. The
default configuration boost::bloom::filter<T, K> =
boost::bloom::filter<T, K, block<unsigned char, 1>>, which corresponds to a
classical Bloom filter, has the best (lowest) FPR among all filters
with the same number of bits per operation, but is also the slowest: a new
subarray is accessed for each bit set/checked. Consult the
benchmarks section to see different tradeoffs between FPR and
performance.
Once a subfilter has been selected, the parameter K' can be tuned
to its optimum value (minimum FPR) if the number of elements that will be inserted is
known in advance, as explained in a dedicated section;
otherwise, low values of K' will generally be faster and preferred to
higher values as long as the resulting FPR is at acceptable levels.
Stride
As we have seen, Subfilter defines the subarray (Block in the case of
block<Block, K'>, Block[K'] for multiblock<Block, K'>) used by
boost::bloom::filter: contiguous portions of the underlying bit array
are then accessed and treated as those subarrays. The Stride parameter
controls the distance in bytes between the initial positions of
consecutive subarrays.
When the default value 0 is used, the stride is automatically set
to the size of the subarrays, and so there’s no overlapping between them.
If Stride is set to a smaller value than that size, contiguous
subarrays superimpose on one another: the level of overlap is larger
for smaller values of Stride, with maximum overlap happening when
Stride is 1 byte.
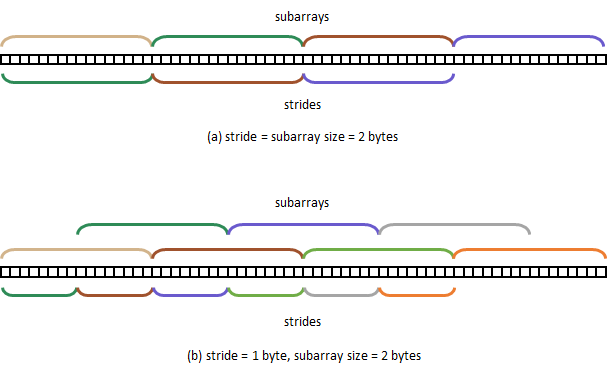
Stride: (a) non-overlapping subarrays, (b) overlapping subarrays.Each subarray is associated to the stride of the same color.
As it happens, overlapping improves (decreases) the resulting FPR with respect to the non-overlapping case, the tradeoff being that subarrays may not be aligned in memory, which can impact performance negatively.
Hash
Unlike other Bloom filter implementations requiring several hash functions per operation,
boost::bloom::filter uses only one.
By default, Boost.ContainerHash is used.
Consult this library’s dedicated section
if you need to extend boost::hash for your own types.
When the provided hash function is of sufficient quality, it is used
as is; otherwise, a bit-mixing post-process is applied to hash values that improves
their statistical properties so that the resulting FPR approaches its
theoretical limit. The hash function is determined to be of high quality
(more precisely, to have the so-called avalanching property) via the
boost::hash_is_avalanching
trait.
Capacity
The size of the filter’s internal array is specified at construction time:
using filter = boost::bloom::filter<std::string, 8>;
filter f(1'000'000); // array of 1'000'000 bits
std::cout << f.capacity(); // >= 1'000'000Note that boost::bloom::filter default constructor specifies a capacity
of zero, which in general won’t be of much use — the assigned array
is null.
Instead of specifying the array’s capacity directly, we can let the library figure it out based on the number of elements we plan to insert and the desired FPR:
// we'll insert 100'000 elements and want a FPR ~ 1%
filter f(100'000, 0.01);
// this is equivalent
filter f2(filter::capacity_for(100'000, 0.01));Be careful when the FPR specified is very small, as the resulting capacity may be too large to fit in memory:
// resulting capacity ~ 1.4E12, out of memory std::bad_alloc is thrown
filter f3(100'000, 1E-50);Once a filter is constructed, its array is fixed (for instance, it won’t
grow dynamically as elements are inserted). The only way to change it is
by assignment/swapping from a different filter, or using reset:
f.reset(2'000'000); // change to 2'000'000 bits and clears the filter
f.reset(100'000, 0.005); // equivalent to reset(filter::capacity_for(100'000, 0.005));
f.reset(); // null array (capacity == 0)Insertion and Lookup
Insertion is done in much the same way as with a traditional container:
f.insert("hello");
f.insert(data.begin(), data.end());Of course, in this context "insertion" does not involve any actual storage of elements into the filter, but rather the setting of bits in the internal array based on the hash values of those elements. Lookup goes as follows:
bool b1 = f.may_contain("hello"); // b1 is true since we actually inserted "hello"
bool b2 = f.may_contain("bye"); // b2 is most likely falseAs its name suggests, may_contain can return true even if the
element has not been previously inserted, that is, it may yield false
positives — this is the essence of probabilistic data structures.
fpr_for provides an estimation of the false positive rate:
// we have inserted 100 elements so far, what's our FPR?
std::cout<< filter::fpr_for(100, f.capacity());Note that in the example we provided the number 100 externally:
boost::bloom::filter does not keep track of the number of elements
that have been inserted — in other words, it does not have a size
operation.
Once inserted, there is no way to remove a specific element from the filter. We can only clear up the filter entirely:
f.clear(); // sets all the bits in the array to zeroBulk Operations
In general, the following code:
f.insert(data.begin(), data.end());is faster than:
for(const auto& x: data) f.insert(x);This is so because the former processes the range in
chunks of size bulk_insert_size
using some internal streamlining techniques in order to reduce execution
time. Similarly, may_contain can be executed
in bulk mode as follows:
f.may_contain(
input.begin(), input.end(), // range of elements to do lookup on
[](value_type& x, bool b) { // called for each of the elements with their lookup result
if(b) std::cout << x << "likely in the filter";
else std::cout << x << "not in the filter";
});Bulk may_contain processes the range in chunks of
bulk_may_contain_size elements.
Bulk mode can increase performance by a factor of 2x or more, but this is very dependent on the filter configuration, the compiler used and the environment, and in some cases it results in a net performance loss. In general, the speedup is higher for larger array sizes. For more information, consult the dedicated benchmark section and associated repo.
Filter Combination
boost::bloom::filters can be combined by doing the OR logical operation
of the bits of their arrays:
filter f2 = ...;
...
f |= f2; // f and f2 must have exactly the same capacityThe result is equivalent to a filter "containing" the set union of the elements
of f and f2. AND combination, on the other hand, results in a filter
holding the intersection of the elements:
filter f3 = ...;
...
f &= f3; // f and f3 must have exactly the same capacityFor AND combination, be aware that the resulting FPR will be in general
worse (higher) than if the filter had been constructed from scratch
by inserting only the common elements — don’t trust fpr_for in this
case.
Direct Access to the Array
The contents of the bit array can be accessed directly with the array
member function, which can be leveraged for filter serialization:
filter f1 = ...;
...
// save filter
std::ofstream out("filter.bin", std::ios::binary);
std::size_t c1=f1.capacity();
out.write(reinterpret_cast<const char*>(&c1), sizeof(c1)); // save capacity (bits)
boost::span<const unsigned char> s1 = f1.array();
out.write(reinterpret_cast<const char*>(s1.data()), s1.size()); // save array
out.close();
// load filter
filter f2;
std::ifstream in("filter.bin", std::ios::binary);
std::size_t c2;
in.read(reinterpret_cast<char*>(&c2), sizeof(c2));
f2.reset(c2); // restore capacity
boost::span<unsigned char> s2 = f2.array();
in.read(reinterpret_cast<char*>(s2.data()), s2.size()); // load array
in.close();Note that array() is a span over unsigned chars whereas
capacities are measured in bits, so array.size() is
capacity() / CHAR_BIT. If you load a serialized filter in a computer
other than the one where it was saved, take into account that
the CPU architectures at each end must have the same
endianness for the
reconstruction to work.
Debugging
Visual Studio Natvis
Add the boost_bloom.natvis visualizer
to your project to allow for user-friendly inspection of boost::bloom::filters.
boost::bloom::filter with boost_bloom.natvis.GDB Pretty-Printer
boost::bloom::filter comes with a dedicated
pretty-printer
for visual inspection when debugging with GDB:
(gdb) print f
$1 = boost::bloom::filter with {capacity = 2000, data = 0x6da840, size = 250} = {[0] = 0 '\000',
[1] = 0 '\000', [2] = 0 '\000', [3] = 0 '\000', [4] = 0 '\000', [5] = 1 '\001'...}
(gdb) # boost::bloom::filter does not have an operator[]. The following expression
(gdb) # is used in place of print f.array()[30]
(gdb) print f[30]
$2 = 128 '\200'Remember to enable pretty-printing in GDB (typically a one-time setup):
(gdb) set print pretty onThe pretty-printer is automatically embedded in the program if your compiled binary
format is ELF and the macro BOOST_ALL_NO_EMBEDDED_GDB_SCRIPTS is not defined;
embedded pretty-printers are enabled for a particular GDB session
with this command (or by default by adding it to your .gdbinit configuration
file):
(gdb) add-auto-load-safe-path <path-to-executable>As an alternative to using the embedded pretty-printer, you can explicitly
load the boost_bloom_printers.py
script:
(gdb) source <path-to-boost>/libs/bloom/extra/boost_bloom_printers.pyChoosing a Filter Configuration
Boost.Bloom offers a plethora of compile-time and run-time configuration options, so it may be difficult to make a choice. If you’re aiming for a given FPR or have a particular capacity in mind and you’d like to choose the most appropriate filter type, the following chart may come handy.
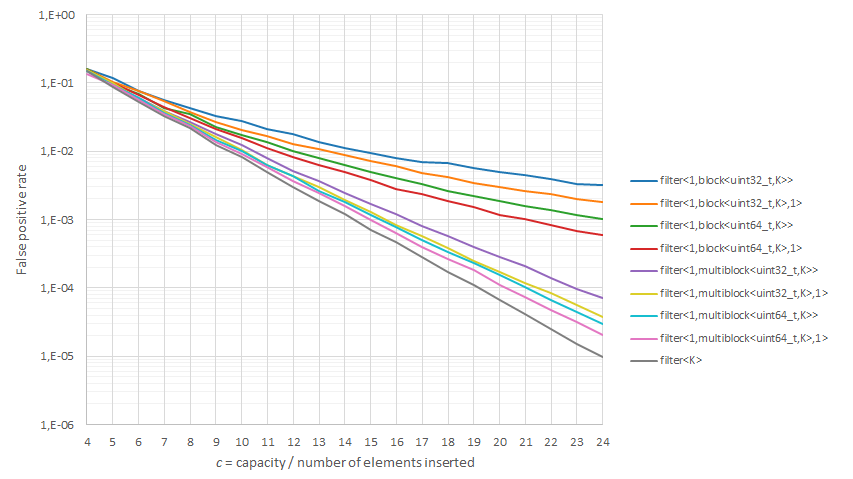
The chart plots FPR vs. c (capacity / number of elements inserted) for several
boost::bloom::filters where K has been set to its optimum value (minimum FPR)
as shown in the table below.
| c = capacity / number of elements inserted | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | |
filter<T,1,block<uint32_t,K>> | 3 | 3 | 3 | 4 | 4 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 6 | 6 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
filter<T,1,block<uint32_t,K>,1> | 2 | 3 | 4 | 4 | 4 | 4 | 5 | 5 | 5 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 7 | 7 | 7 | 7 | 7 |
filter<T,1,block<uint64_t,K>> | 2 | 3 | 4 | 4 | 5 | 5 | 5 | 5 | 5 | 6 | 6 | 6 | 6 | 6 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
filter<T,1,block<uint64_t,K>,1> | 2 | 3 | 4 | 4 | 4 | 5 | 6 | 6 | 6 | 7 | 7 | 7 | 7 | 7 | 8 | 8 | 8 | 8 | 8 | 9 | 9 |
filter<T,1,multiblock<uint32_t,K>> | 3 | 3 | 4 | 5 | 6 | 6 | 8 | 8 | 8 | 8 | 9 | 9 | 9 | 10 | 13 | 13 | 15 | 15 | 15 | 16 | 16 |
filter<T,1,block<uint64_t[8],K>> | 4 | 4 | 4 | 5 | 5 | 6 | 7 | 7 | 7 | 8 | 8 | 9 | 9 | 10 | 10 | 11 | 12 | 12 | 12 | 12 | 12 |
filter<T,1,multiblock<uint32_t,K>,1> | 3 | 3 | 4 | 5 | 6 | 6 | 7 | 7 | 8 | 8 | 9 | 9 | 10 | 10 | 12 | 12 | 14 | 14 | 14 | 14 | 15 |
filter<T,1,block<uint64_t[8],K>,1> | 3 | 3 | 4 | 5 | 6 | 6 | 7 | 7 | 7 | 8 | 8 | 8 | 10 | 11 | 11 | 12 | 12 | 12 | 12 | 12 | 13 |
filter<T,1,multiblock<uint64_t,K>> | 4 | 4 | 5 | 5 | 6 | 6 | 6 | 7 | 8 | 8 | 10 | 10 | 12 | 13 | 14 | 15 | 15 | 15 | 15 | 16 | 17 |
filter<T,1,multiblock<uint64_t,K>,1> | 3 | 3 | 4 | 5 | 5 | 6 | 6 | 7 | 9 | 10 | 10 | 11 | 11 | 12 | 12 | 13 | 13 | 13 | 15 | 16 | 16 |
filter<T,K> | 3 | 4 | 4 | 5 | 5 | 6 | 6 | 8 | 8 | 9 | 10 | 11 | 12 | 13 | 13 | 13 | 14 | 16 | 16 | 16 | 17 |
Let’s see how this can be used by way of an example. Suppose we plan to insert 10M elements and want to keep the FPR at 10−4. The chart gives us five different values of c (the array capacity divided by the number of elements, in our case 10M):
-
filter<T, K>→ c ≅ 19 bits per element -
filter<T, 1, multiblock<uint64_t, K>, 1>→ c ≅ 20 bits per element -
filter<T, 1, multiblock<uint64_t, K>>→ c ≅ 21 bits per element -
filter<T, 1, block<uint64_t[8], K>, 1>→ c ≅ 21 bits per element -
filter<T, 1, multiblock<uint32_t, K>, 1>→ c ≅ 21.5 bits per element -
filter<T, 1, block<uint64_t[8], K>>→ c ≅ 22 bits per element -
filter<T, 1, multiblock<uint32_t, K>>→ c ≅ 23 bits per element
These options have different tradeoffs in terms of space used and performance. If
we choose filter<T, 1, multiblock<uint32_t, K>, 1> as a compromise (or better yet,
filter<T, 1, fast_multiblock32<K>, 1>), the only remaining step is to consult the
value of K in the table for c = 21 or 22, and we get our final configuration:
using my_filter=filter<std::string, 1, fast_multiblock32<14>, 1>;The resulting filter can be constructed in any of the following ways:
// 1) calculate the capacity from the value of c we got from the chart
my_filter f((std::size_t)(10'000'000 * 21.5));
// 2) let the library calculate the capacity from n and target fpr
// expect some deviation from the capacity in 1)
my_filter f(10'000'000, 1E-4);
// 3) equivalent to 2)
my_filter f(my_filter::capacity_for(10'000'000, 1E-4));Benchmarks
(More results in a dedicated repo.)
The tables show the false positive rate and execution times in nanoseconds per operation
for several configurations of boost::bloom::filter<int, ...> where 10M elements have
been inserted.
-
ins.: Insertion.
-
succ. lkp.: Successful lookup (the element is in the filter).
-
uns. lkp.: Unsuccessful lookup (the element is not in the filter, though lookup may return
true). -
mixed lkp.: Mixed lookup (10% successful, 90% unsuccessful).
Filters are constructed with a capacity c * N (bits), so c is the number of
bits used per element. For each combination of c and a given filter configuration, we have
selected the optimum value of K (that yielding the minimum FPR).
Standard release-mode settings are used; AVX2 is indicated for Visual Studio builds
(/arch:AVX2) and GCC/Clang builds (-march=native), which causes
fast_multiblock32 and fast_multiblock64 to use their AVX2 variant.
GCC 14, x64
filter<int,K> |
filter<int,1,block<uint64_t,K>> |
filter<int,1,block<uint64_t,K>,1> |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 6 | 2.1519 | 15.40 | 17.18 | 21.01 | 22.53 | 4 | 3.3467 | 5.04 | 5.67 | 5.65 | 5.63 | 5 | 3.0383 | 5.31 | 5.97 | 5.98 | 6.00 |
| 12 | 9 | 0.3180 | 52.20 | 57.42 | 28.83 | 33.49 | 5 | 1.0300 | 11.45 | 12.50 | 12.56 | 12.47 | 6 | 0.8268 | 12.07 | 12.59 | 12.59 | 12.54 |
| 16 | 11 | 0.0469 | 85.91 | 95.79 | 34.35 | 43.78 | 6 | 0.4034 | 16.94 | 18.74 | 18.73 | 18.72 | 7 | 0.2883 | 19.20 | 19.38 | 19.37 | 19.38 |
| 20 | 14 | 0.0065 | 122.99 | 136.63 | 40.00 | 54.53 | 7 | 0.1887 | 22.76 | 22.40 | 22.40 | 22.38 | 8 | 0.1194 | 23.06 | 25.67 | 25.67 | 25.69 |
filter<int,1,multiblock<uint64_t,K>> |
filter<int,1,multiblock<uint64_t,K>,1> |
filter<int,1,fast_multiblock32<K>> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.4510 | 6.20 | 6.93 | 6.91 | 6.90 | 5 | 2.3157 | 6.98 | 8.73 | 8.72 | 8.75 | 5 | 2.7361 | 4.26 | 4.05 | 4.06 | 4.09 |
| 12 | 8 | 0.4207 | 13.54 | 17.01 | 17.02 | 17.03 | 8 | 0.3724 | 17.59 | 22.15 | 22.21 | 22.10 | 8 | 0.5415 | 8.09 | 8.41 | 8.42 | 8.46 |
| 16 | 11 | 0.0764 | 29.76 | 31.32 | 31.29 | 31.29 | 11 | 0.0642 | 35.49 | 35.18 | 35.16 | 35.16 | 11 | 0.1179 | 19.46 | 21.14 | 15.17 | 16.59 |
| 20 | 13 | 0.0150 | 37.30 | 39.43 | 39.43 | 39.45 | 14 | 0.0122 | 39.98 | 52.28 | 51.49 | 52.16 | 13 | 0.0275 | 21.92 | 24.21 | 17.10 | 18.71 |
filter<int,1,fast_multiblock32<K>,1> |
filter<int,1,fast_multiblock64<K>> |
filter<int,1,fast_multiblock64<K>,1> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.4788 | 4.34 | 4.01 | 4.00 | 4.02 | 5 | 2.4546 | 6.96 | 7.39 | 7.48 | 7.41 | 5 | 2.3234 | 5.87 | 5.85 | 5.85 | 5.86 |
| 12 | 8 | 0.4394 | 8.88 | 8.75 | 8.77 | 8.74 | 8 | 0.4210 | 8.69 | 9.66 | 9.72 | 9.69 | 8 | 0.3754 | 11.26 | 12.49 | 12.48 | 12.47 |
| 16 | 11 | 0.0865 | 18.94 | 20.93 | 14.90 | 16.43 | 11 | 0.0781 | 25.21 | 26.82 | 21.99 | 23.32 | 11 | 0.0642 | 23.97 | 27.41 | 22.21 | 23.47 |
| 20 | 13 | 0.0178 | 21.62 | 24.21 | 16.72 | 18.43 | 13 | 0.0160 | 30.99 | 37.48 | 25.27 | 26.90 | 14 | 0.0110 | 30.44 | 37.40 | 25.38 | 26.93 |
filter<int,1,block<uint64_t[8],K>> |
filter<int,1,block<uint64_t[8],K>,1> |
filter<int,1,multiblock<uint64_t[8],K>> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.3292 | 8.27 | 9.21 | 16.05 | 17.80 | 6 | 2.2986 | 12.49 | 10.04 | 20.31 | 21.25 | 7 | 2.3389 | 15.10 | 15.21 | 15.26 | 15.29 |
| 12 | 7 | 0.4140 | 16.00 | 17.87 | 18.36 | 21.24 | 7 | 0.3845 | 23.85 | 22.82 | 22.12 | 24.50 | 10 | 0.3468 | 29.46 | 31.95 | 31.99 | 31.98 |
| 16 | 9 | 0.0852 | 28.48 | 29.03 | 22.33 | 27.03 | 10 | 0.0714 | 35.97 | 34.60 | 26.73 | 32.18 | 11 | 0.0493 | 44.35 | 50.15 | 50.14 | 50.21 |
| 20 | 12 | 0.0196 | 42.78 | 43.70 | 25.31 | 32.06 | 12 | 0.0152 | 52.29 | 52.03 | 29.21 | 34.86 | 15 | 0.0076 | 69.93 | 74.25 | 74.10 | 74.15 |
Clang 18, x64
filter<int,K> |
filter<int,1,block<uint64_t,K>> |
filter<int,1,block<uint64_t,K>,1> |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 6 | 2.1519 | 15.00 | 15.48 | 20.32 | 21.79 | 4 | 3.3467 | 4.73 | 4.73 | 4.70 | 4.69 | 5 | 3.0383 | 5.64 | 6.25 | 6.23 | 6.24 |
| 12 | 9 | 0.3180 | 47.79 | 49.35 | 26.32 | 31.11 | 5 | 1.0300 | 11.49 | 11.45 | 11.46 | 11.47 | 6 | 0.8268 | 11.70 | 12.80 | 12.81 | 12.82 |
| 16 | 11 | 0.0469 | 86.52 | 87.04 | 31.84 | 40.27 | 6 | 0.4034 | 18.14 | 18.24 | 18.23 | 18.25 | 7 | 0.2883 | 17.03 | 18.96 | 18.96 | 18.99 |
| 20 | 14 | 0.0065 | 119.92 | 119.60 | 36.84 | 52.66 | 7 | 0.1887 | 22.16 | 22.00 | 22.00 | 22.02 | 8 | 0.1194 | 14.02 | 15.27 | 15.27 | 15.25 |
filter<int,1,multiblock<uint64_t,K>> |
filter<int,1,multiblock<uint64_t,K>,1> |
filter<int,1,fast_multiblock32<K>> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.4510 | 5.27 | 6.18 | 6.18 | 6.20 | 5 | 2.3157 | 4.50 | 4.98 | 5.00 | 5.01 | 5 | 2.7361 | 4.14 | 4.05 | 4.06 | 4.08 |
| 12 | 8 | 0.4207 | 8.73 | 10.49 | 10.48 | 10.46 | 8 | 0.3724 | 9.55 | 12.13 | 12.13 | 12.08 | 8 | 0.5415 | 7.94 | 7.63 | 7.64 | 7.62 |
| 16 | 11 | 0.0764 | 18.48 | 22.46 | 22.46 | 22.46 | 11 | 0.0642 | 17.81 | 22.51 | 22.48 | 22.50 | 11 | 0.1179 | 15.25 | 16.61 | 12.59 | 13.95 |
| 20 | 13 | 0.0150 | 23.02 | 29.67 | 29.71 | 29.71 | 14 | 0.0122 | 24.11 | 30.94 | 30.96 | 30.98 | 13 | 0.0275 | 16.95 | 18.48 | 13.96 | 15.71 |
filter<int,1,fast_multiblock32<K>,1> |
filter<int,1,fast_multiblock64<K>> |
filter<int,1,fast_multiblock64<K>,1> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.4788 | 3.68 | 3.45 | 3.42 | 3.39 | 5 | 2.4546 | 5.19 | 5.56 | 5.57 | 5.59 | 5 | 2.3234 | 5.22 | 5.39 | 5.37 | 5.38 |
| 12 | 8 | 0.4394 | 7.90 | 7.93 | 7.99 | 7.92 | 8 | 0.4210 | 9.32 | 9.97 | 9.97 | 9.99 | 8 | 0.3754 | 10.96 | 12.42 | 12.43 | 12.43 |
| 16 | 11 | 0.0865 | 14.44 | 16.40 | 12.03 | 13.44 | 11 | 0.0781 | 19.44 | 21.68 | 17.18 | 19.06 | 11 | 0.0642 | 18.27 | 21.52 | 17.03 | 18.84 |
| 20 | 13 | 0.0178 | 15.88 | 18.32 | 13.35 | 15.19 | 13 | 0.0160 | 24.18 | 29.36 | 18.90 | 21.11 | 14 | 0.0110 | 24.52 | 26.84 | 18.96 | 20.93 |
filter<int,1,block<uint64_t[8],K>> |
filter<int,1,block<uint64_t[8],K>,1> |
filter<int,1,multiblock<uint64_t[8],K>> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.3292 | 7.46 | 7.85 | 15.05 | 17.13 | 6 | 2.2986 | 12.93 | 10.03 | 19.77 | 20.99 | 7 | 2.3389 | 13.53 | 13.34 | 13.37 | 13.32 |
| 12 | 7 | 0.4140 | 18.93 | 17.17 | 18.34 | 21.21 | 7 | 0.3845 | 23.02 | 19.22 | 19.54 | 22.44 | 10 | 0.3468 | 32.32 | 34.01 | 34.01 | 33.94 |
| 16 | 9 | 0.0852 | 29.47 | 27.26 | 21.68 | 25.51 | 10 | 0.0714 | 36.97 | 33.58 | 24.96 | 29.48 | 11 | 0.0493 | 44.86 | 49.30 | 49.36 | 49.36 |
| 20 | 12 | 0.0196 | 44.02 | 36.49 | 25.43 | 32.45 | 12 | 0.0152 | 53.64 | 41.22 | 26.37 | 32.60 | 15 | 0.0076 | 73.24 | 70.58 | 70.14 | 70.39 |
Clang 15, ARM64
filter<int,K> |
filter<int,1,block<uint64_t,K>> |
filter<int,1,block<uint64_t,K>,1> |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 6 | 2.1519 | 7.84 | 6.33 | 13.07 | 13.65 | 4 | 3.3467 | 2.12 | 2.07 | 2.07 | 2.08 | 5 | 3.0383 | 2.18 | 2.10 | 2.09 | 2.09 |
| 12 | 9 | 0.3180 | 13.12 | 11.56 | 16.21 | 17.94 | 5 | 1.0300 | 3.75 | 3.82 | 3.57 | 3.92 | 6 | 0.8268 | 3.48 | 3.24 | 3.19 | 3.21 |
| 16 | 11 | 0.0469 | 31.85 | 25.68 | 18.28 | 22.44 | 6 | 0.4034 | 7.19 | 6.65 | 6.41 | 6.58 | 7 | 0.2883 | 6.78 | 6.16 | 6.13 | 6.01 |
| 20 | 14 | 0.0065 | 53.59 | 39.04 | 20.54 | 27.09 | 7 | 0.1887 | 9.40 | 8.05 | 8.11 | 7.94 | 8 | 0.1194 | 7.73 | 6.32 | 6.83 | 6.65 |
filter<int,1,multiblock<uint64_t,K>> |
filter<int,1,multiblock<uint64_t,K>,1> |
filter<int,1,fast_multiblock32<K>> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.4510 | 2.75 | 2.63 | 2.64 | 2.60 | 5 | 2.3157 | 2.77 | 2.68 | 2.69 | 2.67 | 5 | 2.7361 | 2.44 | 2.62 | 2.66 | 2.64 |
| 12 | 8 | 0.4207 | 4.11 | 4.24 | 4.55 | 4.35 | 8 | 0.3724 | 4.34 | 4.66 | 4.54 | 4.60 | 8 | 0.5415 | 2.68 | 3.31 | 3.33 | 3.33 |
| 16 | 11 | 0.0764 | 10.25 | 9.42 | 9.30 | 10.01 | 11 | 0.0642 | 11.16 | 9.82 | 10.07 | 9.91 | 11 | 0.1179 | 8.25 | 8.07 | 5.90 | 6.98 |
| 20 | 13 | 0.0150 | 14.14 | 12.81 | 12.90 | 12.86 | 14 | 0.0122 | 15.87 | 13.62 | 13.61 | 13.90 | 13 | 0.0275 | 10.31 | 11.20 | 6.69 | 7.76 |
filter<int,1,fast_multiblock32<K>,1> |
filter<int,1,fast_multiblock64<K>> |
filter<int,1,fast_multiblock64<K>,1> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.4788 | 2.40 | 2.57 | 2.62 | 2.60 | 5 | 2.4510 | 2.79 | 2.65 | 2.67 | 2.64 | 5 | 2.3157 | 2.76 | 2.67 | 2.70 | 2.69 |
| 12 | 8 | 0.4394 | 3.27 | 3.14 | 3.11 | 3.36 | 8 | 0.4207 | 4.08 | 4.64 | 4.36 | 4.39 | 8 | 0.3724 | 4.36 | 4.78 | 4.93 | 4.94 |
| 16 | 11 | 0.0865 | 7.87 | 8.12 | 6.03 | 6.68 | 11 | 0.0764 | 9.78 | 9.01 | 9.01 | 9.58 | 11 | 0.0642 | 11.18 | 9.98 | 10.05 | 10.00 |
| 20 | 13 | 0.0178 | 10.28 | 10.90 | 6.43 | 7.91 | 13 | 0.0150 | 15.65 | 12.84 | 13.19 | 12.87 | 14 | 0.0122 | 15.83 | 13.80 | 13.05 | 12.52 |
filter<int,1,block<uint64_t[8],K>> |
filter<int,1,block<uint64_t[8],K>,1> |
filter<int,1,multiblock<uint64_t[8],K>> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.3292 | 4.71 | 4.40 | 11.49 | 12.49 | 6 | 2.2986 | 9.07 | 5.03 | 13.73 | 14.25 | 7 | 2.3389 | 9.10 | 7.06 | 7.05 | 7.05 |
| 12 | 7 | 0.4140 | 9.22 | 8.50 | 12.67 | 15.09 | 7 | 0.3845 | 13.27 | 8.10 | 13.37 | 15.47 | 10 | 0.3468 | 14.73 | 12.49 | 12.21 | 12.53 |
| 16 | 9 | 0.0852 | 16.66 | 13.68 | 14.34 | 16.94 | 10 | 0.0714 | 24.53 | 16.40 | 16.90 | 20.26 | 11 | 0.0493 | 27.25 | 23.91 | 23.51 | 24.00 |
| 20 | 12 | 0.0196 | 22.15 | 16.19 | 15.03 | 18.30 | 12 | 0.0152 | 27.21 | 19.06 | 16.37 | 20.16 | 15 | 0.0076 | 45.60 | 35.50 | 35.49 | 35.50 |
VS 2022, x64
filter<int,K> |
filter<int,1,block<uint64_t,K>> |
filter<int,1,block<uint64_t,K>,1> |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 6 | 2.1519 | 15.74 | 39.75 | 24.15 | 27.06 | 4 | 3.3467 | 4.66 | 4.87 | 4.84 | 4.83 | 5 | 3.0383 | 4.93 | 4.83 | 4.61 | 4.57 |
| 12 | 9 | 0.3180 | 39.82 | 39.21 | 20.53 | 23.85 | 5 | 1.0300 | 8.55 | 8.28 | 8.44 | 8.35 | 6 | 0.8268 | 9.77 | 9.51 | 9.46 | 9.42 |
| 16 | 11 | 0.0469 | 71.07 | 83.07 | 26.88 | 34.78 | 6 | 0.4034 | 16.76 | 14.54 | 14.64 | 14.63 | 7 | 0.2883 | 17.56 | 16.92 | 16.90 | 16.95 |
| 20 | 14 | 0.0065 | 103.76 | 118.04 | 31.19 | 42.73 | 7 | 0.1887 | 19.82 | 18.42 | 18.45 | 18.55 | 8 | 0.1194 | 20.96 | 22.75 | 22.79 | 22.75 |
filter<int,1,multiblock<uint64_t,K>> |
filter<int,1,multiblock<uint64_t,K>,1> |
filter<int,1,fast_multiblock32<K>> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.4510 | 7.06 | 4.81 | 4.60 | 4.67 | 5 | 2.3157 | 7.85 | 5.28 | 5.03 | 4.98 | 5 | 2.7361 | 4.06 | 3.57 | 3.57 | 3.55 |
| 12 | 8 | 0.4207 | 12.78 | 11.44 | 11.42 | 11.32 | 8 | 0.3724 | 19.79 | 13.42 | 13.63 | 13.60 | 8 | 0.5415 | 6.09 | 6.06 | 5.23 | 6.43 |
| 16 | 11 | 0.0764 | 27.65 | 24.32 | 24.34 | 24.46 | 11 | 0.0642 | 31.18 | 29.82 | 29.78 | 29.84 | 11 | 0.1179 | 14.42 | 15.78 | 11.22 | 12.37 |
| 20 | 13 | 0.0150 | 36.26 | 35.31 | 35.21 | 35.25 | 14 | 0.0122 | 39.58 | 37.78 | 37.75 | 37.78 | 13 | 0.0275 | 16.33 | 17.85 | 12.38 | 13.61 |
filter<int,1,fast_multiblock32<K>,1> |
filter<int,1,fast_multiblock64<K>> |
filter<int,1,fast_multiblock64<K>,1> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.4788 | 3.30 | 7.65 | 7.66 | 7.65 | 5 | 2.4546 | 4.24 | 3.70 | 3.47 | 3.45 | 5 | 2.3234 | 4.62 | 3.77 | 3.62 | 3.55 |
| 12 | 8 | 0.4394 | 8.19 | 8.95 | 7.71 | 8.57 | 8 | 0.4210 | 8.66 | 8.26 | 7.42 | 8.71 | 8 | 0.3754 | 10.37 | 9.63 | 8.42 | 9.19 |
| 16 | 11 | 0.0865 | 14.86 | 15.64 | 11.14 | 12.09 | 11 | 0.0781 | 23.99 | 19.63 | 16.58 | 17.51 | 11 | 0.0642 | 21.43 | 19.33 | 16.35 | 17.11 |
| 20 | 13 | 0.0178 | 17.75 | 17.90 | 12.37 | 13.80 | 13 | 0.0160 | 28.54 | 26.97 | 18.98 | 20.10 | 14 | 0.0110 | 28.58 | 26.89 | 19.02 | 19.88 |
filter<int,1,block<uint64_t[8],K>> |
filter<int,1,block<uint64_t[8],K>,1> |
filter<int,1,multiblock<uint64_t[8],K>> |
||||||||||||||||
| c | K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | FPR [%] |
ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 2.3292 | 8.16 | 7.72 | 12.16 | 13.28 | 6 | 2.2986 | 10.74 | 9.89 | 14.82 | 15.44 | 7 | 2.3389 | 11.56 | 9.94 | 9.93 | 9.72 |
| 12 | 7 | 0.4140 | 14.41 | 14.90 | 15.39 | 17.45 | 7 | 0.3845 | 22.28 | 20.72 | 18.53 | 20.75 | 10 | 0.3468 | 21.52 | 21.28 | 21.28 | 21.30 |
| 16 | 9 | 0.0852 | 27.96 | 28.29 | 20.87 | 24.11 | 10 | 0.0714 | 34.15 | 33.63 | 20.57 | 25.46 | 11 | 0.0493 | 42.62 | 40.23 | 40.30 | 40.28 |
| 20 | 12 | 0.0196 | 36.03 | 35.12 | 23.05 | 28.27 | 12 | 0.0152 | 42.51 | 41.13 | 21.94 | 28.03 | 15 | 0.0076 | 68.84 | 64.56 | 64.67 | 64.67 |
Bulk operations
(More results in a dedicated repo.)
The following tables show the relative performance of the insertion and lookup operations described before when they’re executed in bulk mode. Values greater than 1.0 indicate that the bulk mode is faster (which is not always the case).
GCC 14, x64
filter<int,K> |
filter<int,1,block<uint64_t,K>> |
filter<int,1,block<uint64_t,K>,1> |
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 6 | 1.00 | 0.78 | 2.11 | 1.43 | 4 | 1.20 | 1.34 | 1.21 | 1.32 | 5 | 1.09 | 1.34 | 1.25 | 1.22 |
| 12 | 9 | 1.86 | 1.54 | 2.27 | 1.38 | 5 | 2.07 | 2.26 | 2.10 | 2.02 | 6 | 1.89 | 1.91 | 1.90 | 1.88 |
| 16 | 11 | 2.22 | 2.08 | 2.45 | 1.46 | 6 | 2.92 | 2.97 | 2.86 | 2.82 | 7 | 2.69 | 2.65 | 2.66 | 2.66 |
| 20 | 14 | 2.19 | 2.24 | 2.57 | 1.43 | 7 | 3.50 | 3.24 | 3.15 | 3.33 | 8 | 2.71 | 3.06 | 3.29 | 3.16 |
filter<int,1,multiblock<uint64_t,K>> |
filter<int,1,multiblock<uint64_t,K>,1> |
filter<int,1,fast_multiblock32<K>> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.32 | 1.32 | 1.33 | 1.34 | 5 | 1.27 | 1.54 | 1.54 | 1.55 | 5 | 1.28 | 1.31 | 1.32 | 1.38 |
| 12 | 8 | 1.98 | 2.13 | 2.35 | 2.13 | 8 | 2.28 | 2.65 | 2.66 | 2.60 | 8 | 2.09 | 2.09 | 2.25 | 2.16 |
| 16 | 11 | 2.15 | 2.55 | 2.52 | 2.48 | 11 | 1.67 | 2.47 | 2.48 | 2.48 | 11 | 2.70 | 3.01 | 3.02 | 3.06 |
| 20 | 13 | 2.07 | 2.29 | 2.29 | 2.28 | 14 | 2.24 | 2.89 | 2.74 | 2.80 | 13 | 2.44 | 2.66 | 2.58 | 2.64 |
filter<int,1,fast_multiblock32<K>,1> |
filter<int,1,fast_multiblock64<K>> |
filter<int,1,fast_multiblock64<K>,1> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.12 | 1.22 | 1.18 | 1.17 | 5 | 1.28 | 1.27 | 1.26 | 1.34 | 5 | 1.24 | 1.27 | 1.29 | 1.29 |
| 12 | 8 | 2.01 | 2.10 | 2.10 | 2.10 | 8 | 2.18 | 2.25 | 2.01 | 2.12 | 8 | 2.19 | 2.41 | 2.44 | 2.41 |
| 16 | 11 | 2.62 | 2.95 | 2.96 | 2.95 | 11 | 1.96 | 2.15 | 2.15 | 2.15 | 11 | 1.82 | 2.12 | 2.12 | 2.11 |
| 20 | 13 | 2.35 | 2.61 | 2.53 | 2.60 | 13 | 1.77 | 1.89 | 1.89 | 1.89 | 14 | 1.69 | 1.87 | 1.87 | 1.87 |
filter<int,1,block<uint64_t[8],K>> |
filter<int,1,block<uint64_t[8],K>,1> |
filter<int,1,multiblock<uint64_t[8],K>> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.25 | 1.37 | 1.26 | 1.35 | 6 | 0.99 | 1.38 | 1.38 | 1.52 | 7 | 1.21 | 1.24 | 1.25 | 1.25 |
| 12 | 7 | 1.84 | 1.81 | 1.80 | 1.80 | 7 | 1.61 | 2.35 | 2.41 | 2.43 | 10 | 1.50 | 1.65 | 1.65 | 1.65 |
| 16 | 9 | 2.92 | 2.56 | 2.56 | 2.56 | 10 | 2.40 | 3.44 | 3.43 | 3.42 | 11 | 1.39 | 1.65 | 1.64 | 1.64 |
| 20 | 12 | 3.50 | 3.27 | 3.27 | 3.27 | 12 | 3.21 | 4.03 | 4.03 | 4.03 | 15 | 1.21 | 1.42 | 1.42 | 1.41 |
Clang 18, x64
filter<int,K> |
filter<int,1,block<uint64_t,K>> |
filter<int,1,block<uint64_t,K>,1> |
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 6 | 1.06 | 0.88 | 2.58 | 1.71 | 4 | 1.50 | 1.38 | 1.39 | 1.39 | 5 | 1.23 | 1.32 | 1.36 | 1.32 |
| 12 | 9 | 1.90 | 1.63 | 2.28 | 1.46 | 5 | 2.46 | 2.32 | 2.32 | 2.29 | 6 | 2.11 | 2.35 | 2.35 | 2.35 |
| 16 | 11 | 2.25 | 2.01 | 2.39 | 1.43 | 6 | 3.60 | 3.40 | 3.44 | 3.40 | 7 | 2.75 | 3.13 | 3.13 | 3.13 |
| 20 | 14 | 2.15 | 2.18 | 2.50 | 1.38 | 7 | 3.95 | 3.80 | 3.81 | 3.80 | 8 | 1.78 | 2.00 | 1.99 | 2.00 |
filter<int,1,multiblock<uint64_t,K>> |
filter<int,1,multiblock<uint64_t,K>,1> |
filter<int,1,fast_multiblock32<K>> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.20 | 1.32 | 1.34 | 1.34 | 5 | 1.25 | 1.54 | 1.54 | 1.54 | 5 | 1.22 | 1.32 | 1.31 | 1.29 |
| 12 | 8 | 2.64 | 2.59 | 2.61 | 2.60 | 8 | 2.09 | 2.59 | 2.65 | 2.64 | 8 | 2.46 | 2.58 | 2.59 | 2.58 |
| 16 | 11 | 1.66 | 1.96 | 1.93 | 1.96 | 11 | 1.55 | 1.87 | 1.85 | 1.84 | 11 | 2.36 | 2.68 | 2.68 | 2.68 |
| 20 | 13 | 1.49 | 1.88 | 1.87 | 1.89 | 14 | 1.48 | 1.86 | 1.88 | 1.91 | 13 | 1.78 | 2.09 | 2.09 | 2.09 |
filter<int,1,fast_multiblock32<K>,1> |
filter<int,1,fast_multiblock64<K>> |
filter<int,1,fast_multiblock64<K>,1> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.29 | 1.31 | 1.36 | 1.31 | 5 | 1.34 | 1.48 | 1.48 | 1.47 | 5 | 1.30 | 1.41 | 1.45 | 1.40 |
| 12 | 8 | 1.96 | 2.03 | 2.05 | 2.02 | 8 | 2.48 | 2.45 | 2.42 | 2.45 | 8 | 2.34 | 2.67 | 2.68 | 2.67 |
| 16 | 11 | 2.26 | 2.65 | 2.66 | 2.65 | 11 | 1.66 | 1.87 | 1.88 | 1.85 | 11 | 1.58 | 1.81 | 1.81 | 1.80 |
| 20 | 13 | 1.74 | 2.04 | 2.04 | 2.03 | 13 | 1.46 | 1.89 | 1.89 | 1.89 | 14 | 1.45 | 1.79 | 1.79 | 1.78 |
filter<int,1,block<uint64_t[8],K>> |
filter<int,1,block<uint64_t[8],K>,1> |
filter<int,1,multiblock<uint64_t[8],K>> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.70 | 1.66 | 1.69 | 1.68 | 6 | 1.02 | 1.54 | 1.54 | 1.54 | 7 | 1.09 | 1.18 | 1.17 | 1.18 |
| 12 | 7 | 2.16 | 2.14 | 2.13 | 2.14 | 7 | 1.59 | 2.53 | 2.53 | 2.53 | 10 | 1.44 | 1.58 | 1.58 | 1.57 |
| 16 | 9 | 3.09 | 2.95 | 2.96 | 2.95 | 10 | 2.29 | 3.82 | 3.83 | 3.82 | 11 | 1.36 | 1.59 | 1.58 | 1.60 |
| 20 | 12 | 3.69 | 3.44 | 3.44 | 3.41 | 12 | 3.28 | 4.16 | 4.16 | 4.16 | 15 | 1.24 | 1.32 | 1.32 | 1.32 |
Clang 15, ARM64
filter<int,K> |
filter<int,1,block<uint64_t,K>> |
filter<int,1,block<uint64_t,K>,1> |
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 6 | 0.89 | 0.68 | 3.16 | 2.13 | 4 | 1.28 | 1.32 | 1.29 | 1.31 | 5 | 0.98 | 1.18 | 1.17 | 1.17 |
| 12 | 9 | 1.03 | 0.87 | 3.08 | 2.03 | 5 | 1.97 | 2.05 | 2.03 | 2.12 | 6 | 1.42 | 1.72 | 1.66 | 1.62 |
| 16 | 11 | 1.39 | 1.25 | 2.44 | 1.41 | 6 | 2.75 | 3.11 | 2.94 | 3.07 | 7 | 1.92 | 2.05 | 2.05 | 1.94 |
| 20 | 14 | 1.42 | 1.16 | 2.18 | 1.04 | 7 | 2.93 | 3.10 | 2.97 | 3.34 | 8 | 1.76 | 1.87 | 1.67 | 1.92 |
filter<int,1,multiblock<uint64_t,K>> |
filter<int,1,multiblock<uint64_t,K>,1> |
filter<int,1,fast_multiblock32<K>> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.09 | 1.28 | 1.27 | 1.28 | 5 | 1.04 | 1.29 | 1.28 | 1.31 | 5 | 1.13 | 1.47 | 1.47 | 1.46 |
| 12 | 8 | 2.04 | 2.33 | 1.99 | 2.24 | 8 | 1.49 | 1.98 | 1.97 | 2.10 | 8 | 1.72 | 2.33 | 2.23 | 2.13 |
| 16 | 11 | 2.01 | 2.25 | 2.31 | 2.33 | 11 | 1.75 | 2.15 | 2.18 | 2.14 | 11 | 2.02 | 2.27 | 2.46 | 2.71 |
| 20 | 13 | 2.19 | 2.32 | 2.49 | 2.22 | 14 | 2.03 | 2.52 | 2.42 | 2.42 | 13 | 1.95 | 2.70 | 2.66 | 2.71 |
filter<int,1,fast_multiblock32<K>,1> |
filter<int,1,fast_multiblock64<K>> |
filter<int,1,fast_multiblock64<K>,1> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.12 | 1.47 | 1.43 | 1.44 | 5 | 1.10 | 1.29 | 1.26 | 1.28 | 5 | 1.05 | 1.33 | 1.31 | 1.31 |
| 12 | 8 | 1.50 | 1.67 | 1.62 | 1.71 | 8 | 2.11 | 2.18 | 2.24 | 2.23 | 8 | 1.48 | 2.10 | 2.19 | 1.99 |
| 16 | 11 | 2.24 | 2.37 | 2.72 | 2.76 | 11 | 2.11 | 2.16 | 2.17 | 2.17 | 11 | 2.00 | 2.18 | 2.17 | 2.14 |
| 20 | 13 | 2.02 | 2.65 | 2.67 | 2.71 | 13 | 2.16 | 2.32 | 2.33 | 2.34 | 14 | 2.16 | 2.40 | 2.41 | 2.40 |
filter<int,1,block<uint64_t[8],K>> |
filter<int,1,block<uint64_t[8],K>,1> |
filter<int,1,multiblock<uint64_t[8],K>> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.33 | 1.76 | 1.75 | 1.78 | 6 | 1.49 | 1.57 | 1.56 | 1.58 | 7 | 1.16 | 1.31 | 1.30 | 1.30 |
| 12 | 7 | 1.78 | 2.55 | 2.55 | 2.55 | 7 | 1.97 | 2.30 | 2.29 | 2.29 | 10 | 1.29 | 1.45 | 1.45 | 1.46 |
| 16 | 9 | 2.66 | 3.70 | 3.69 | 3.70 | 10 | 2.62 | 3.49 | 3.47 | 3.65 | 11 | 1.55 | 1.55 | 1.55 | 1.55 |
| 20 | 12 | 3.10 | 4.08 | 4.08 | 4.14 | 12 | 3.25 | 4.40 | 4.40 | 4.46 | 15 | 1.72 | 1.60 | 1.60 | 1.60 |
VS 2022, x64
filter<int,K> |
filter<int,1,block<uint64_t,K>> |
filter<int,1,block<uint64_t,K>,1> |
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 6 | 0.92 | 0.69 | 2.11 | 1.33 | 4 | 1.50 | 3.79 | 3.77 | 3.77 | 5 | 3.32 | 1.29 | 1.29 | 1.28 |
| 12 | 9 | 1.35 | 0.80 | 2.14 | 1.15 | 5 | 1.91 | 1.66 | 1.66 | 1.70 | 6 | 2.16 | 0.94 | 0.97 | 0.95 |
| 16 | 11 | 2.20 | 3.09 | 3.57 | 2.13 | 6 | 4.32 | 3.52 | 3.49 | 3.51 | 7 | 3.01 | 3.92 | 3.93 | 3.93 |
| 20 | 14 | 1.86 | 2.60 | 2.64 | 1.45 | 7 | 4.84 | 4.20 | 4.19 | 4.18 | 8 | 3.05 | 3.92 | 3.90 | 3.91 |
filter<int,1,multiblock<uint64_t,K>> |
filter<int,1,multiblock<uint64_t,K>,1> |
filter<int,1,fast_multiblock32<K>> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.57 | 1.15 | 1.16 | 1.16 | 5 | 1.23 | 1.43 | 1.43 | 1.43 | 5 | 1.24 | 0.88 | 0.87 | 0.88 |
| 12 | 8 | 1.93 | 4.55 | 4.53 | 4.53 | 8 | 1.88 | 2.85 | 2.79 | 2.85 | 8 | 2.39 | 2.03 | 2.02 | 2.01 |
| 16 | 11 | 3.90 | 4.65 | 4.68 | 4.76 | 11 | 2.35 | 1.54 | 1.55 | 1.50 | 11 | 1.25 | 0.83 | 0.83 | 0.83 |
| 20 | 13 | 3.80 | 3.23 | 3.26 | 3.02 | 14 | 2.27 | 2.45 | 2.44 | 2.32 | 13 | 1.26 | 1.11 | 1.10 | 1.11 |
filter<int,1,fast_multiblock32<K>,1> |
filter<int,1,fast_multiblock64<K>> |
filter<int,1,fast_multiblock64<K>,1> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.20 | 3.26 | 3.26 | 3.25 | 5 | 0.52 | 0.97 | 0.97 | 0.97 | 5 | 1.14 | 3.61 | 3.61 | 3.62 |
| 12 | 8 | 1.50 | 2.22 | 2.21 | 2.23 | 8 | 2.17 | 4.37 | 4.35 | 4.37 | 8 | 1.40 | 4.08 | 4.03 | 4.06 |
| 16 | 11 | 1.36 | 1.30 | 1.30 | 1.30 | 11 | 2.69 | 0.81 | 0.78 | 0.82 | 11 | 2.83 | 1.69 | 1.59 | 1.48 |
| 20 | 13 | 1.35 | 1.20 | 1.21 | 1.20 | 13 | 1.54 | 1.58 | 1.86 | 1.75 | 14 | 2.44 | 1.45 | 1.53 | 1.58 |
filter<int,1,block<uint64_t[8],K>> |
filter<int,1,block<uint64_t[8],K>,1> |
filter<int,1,multiblock<uint64_t[8],K>> |
|||||||||||||
| c | K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
K | ins. | succ. lkp. |
uns. lkp. |
mixed lkp. |
| 8 | 5 | 1.42 | 1.37 | 1.37 | 1.37 | 6 | 1.09 | 0.32 | 0.33 | 0.32 | 7 | 1.58 | 0.43 | 0.43 | 0.42 |
| 12 | 7 | 3.14 | 1.55 | 1.57 | 1.57 | 7 | 1.67 | 0.66 | 0.66 | 0.66 | 10 | 1.11 | 1.33 | 1.33 | 1.33 |
| 16 | 9 | 3.66 | 2.76 | 2.74 | 2.75 | 10 | 1.64 | 1.26 | 1.26 | 1.25 | 11 | 1.26 | 0.99 | 0.99 | 0.99 |
| 20 | 12 | 3.33 | 3.25 | 3.24 | 3.25 | 12 | 1.83 | 1.68 | 1.68 | 1.68 | 15 | 1.23 | 1.55 | 1.56 | 1.55 |
Reference
<boost/bloom/filter.hpp>
Defines boost::bloom::filter
and associated functions.
namespace boost{
namespace bloom{
template<
typename T, std::size_t K,
typename Subfilter = block<unsigned char, 1>, std::size_t Stride = 0,
typename Hash = boost::hash<T>,
typename Allocator = std::allocator<unsigned char>
>
class filter;
template<
typename T, std::size_t K, typename SF, std::size_t S, typename H, typename A
>
bool operator==(
const filter<T, K, SF, S, H, A>& x, const filter<T, K, SF, S, H, A>& y);
template<
typename T, std::size_t K, typename SF, std::size_t S, typename H, typename A
>
bool operator!=(
const filter<T, K, SF, S, H, A>& x, const filter<T, K, SF, S, H, A>& y);
template<
typename T, std::size_t K, typename SF, std::size_t S, typename H, typename A
>
void swap(filter<T, K, SF, S, H, A>& x, filter<T, K, SF, S, H, A>& y)
noexcept(noexcept(x.swap(y)));
} // namespace bloom
} // namespace boost
Class Template filter
boost::bloom::filter — A data structure that supports element insertion
and probabilistic lookup, where an element can be determined to be in the filter
with high confidence or else not be with absolute certainty. The probability
that lookup erroneously classifies a non-present element as present is called
the filter’s false positive rate (FPR).
boost::bloom::filter maintains an internal array of m bits where m is the
filter’s capacity. Unlike traditional containers, inserting an
element x does not store a copy of x within the filter, but rather results
in a fixed number of bits in the array being set to one, where the positions
of the bits are pseudorandomly produced from the hash value of x. Lookup
for y simply checks whether all the bits associated to y are actually set.
-
For a given filter, the FPR increases as new elements are inserted.
-
For a given number of inserted elements, a filter with higher capacity has a lower FPR.
By convention, we say that a filter is empty if its capacity is zero or all the bits in the internal array are set to zero.
Synopsis
// #include <boost/bloom/filter.hpp>
namespace boost{
namespace bloom{
template<
typename T, std::size_t K,
typename Subfilter = block<unsigned char, 1>, std::size_t Stride = 0,
typename Hash = boost::hash<T>,
typename Allocator = std::allocator<unsigned char>
>
class filter
{
public:
// types and constants
using value_type = T;
static constexpr std::size_t k = K;
using subfilter = Subfilter;
static constexpr std::size_t stride = see below;
using hasher = Hash;
using allocator_type = Allocator;
using size_type = std::size_t;
using difference_type = std::ptrdiff_t;
using reference = value_type&;
using const_reference = const value_type&;
using pointer = value_type*;
using const_pointer = const value_type*;
static constexpr std::size_t
bulk_insert_size = implementation-defined;
static constexpr std::size_t
bulk_may_contain_size = implementation-defined;
// construct/copy/destroy
filter();
explicit filter(
size_type m, const hasher& h = hasher(),
const allocator_type& al = allocator_type());
filter(
size_type n, double fpr, const hasher& h = hasher(),
const allocator_type& al = allocator_type());
template<typename InputIterator>
filter(
InputIterator first, InputIterator last,
size_type m, const hasher& h = hasher(),
const allocator_type& al = allocator_type());
template<typename InputIterator>
filter(
InputIterator first, InputIterator last,
size_type n, double fpr, const hasher& h = hasher(),
const allocator_type& al = allocator_type());
filter(const filter& x);
filter(filter&& x);
template<typename InputIterator>
filter(
InputIterator first, InputIterator last,
size_type m, const allocator_type& al);
template<typename InputIterator>
filter(
InputIterator first, InputIterator last,
size_type n, double fpr, const allocator_type& al);
explicit filter(const allocator_type& al);
filter(const filter& x, const allocator_type& al);
filter(filter&& x, const allocator_type& al);
filter(
std::initializer_list<value_type> il,
size_type m, const hasher& h = hasher(),
const allocator_type& al = allocator_type());
filter(
std::initializer_list<value_type> il,
size_type n, double fpr, const hasher& h = hasher(),
const allocator_type& al = allocator_type());
filter(size_type m, const allocator_type& al);
filter(size_type n, double fpr, const allocator_type& al);
filter(
std::initializer_list<value_type> il,
size_type m, const allocator_type& al);
filter(
std::initializer_list<value_type> il,
size_type n, double fpr, const allocator_type& al);
~filter();
filter& operator=(const filter& x);
filter& operator=(filter&& x)
noexcept(
std::allocator_traits<Allocator>::is_always_equal::value ||
std::allocator_traits<Allocator>::propagate_on_container_move_assignment::value);
filter& operator=(std::initializer_list<value_type> il);
allocator_type get_allocator() const noexcept;
// capacity
size_type capacity() const noexcept;
static size_type capacity_for(size_type n, double fpr);
static double fpr_for(size_type n,size_type m)
// data access
boost::span<unsigned char> array() noexcept;
boost::span<const unsigned char> array() const noexcept;
// modifiers
void insert(const value_type& x);
template<typename U>
void insert(const U& x);
template<typename InputIterator>
void insert(InputIterator first, InputIterator last);
void insert(std::initializer_list<value_type> il);
void swap(filter& x)
noexcept(std::allocator_traits<Allocator>::is_always_equal::value ||
std::allocator_traits<Allocator>::propagate_on_container_swap::value);
void clear() noexcept;
void reset(size_type m = 0);
void reset(size_type n, double fpr);
filter& operator&=(const filter& x);
filter& operator|=(const filter& x);
// observers
hasher hash_function() const;
// lookup
bool may_contain(const value_type& x) const;
template<typename U>
bool may_contain(const U& x) const;
template<typename ForwardIterator, typename F>
void may_contain(ForwardIterator first, ForwardIterator last, F f) const;
};
} // namespace bloom
} // namespace boost
Description
Template Parameters
|
The cv-unqualified object type of the elements inserted into the filter. |
|
Number of times the associated subfilter is invoked per element upon insertion or lookup.
|
|
A subfilter type providing the exact algorithm for
bit setting/checking into the filter’s internal array. The subfilter is invoked |
|
Distance in bytes between the initial positions of consecutive subarrays.
If |
|
A Hash type over |
|
An Allocator whose value type is
|
Allocation and deallocation of the internal array is done through an internal copy of the
provided allocator. If stride is a
multiple of a = alignof(Subfilter::value_type), the array is byte-aligned to
max(64, a).
If boost::hash_is_avalanching<Hash>::value
is true and sizeof(std::size_t) >= 8,
the hash function is used as-is; otherwise, a bit-mixing post-processing stage
is added to increase the quality of hashing at the expense of extra computational cost.
Exception Safety Guarantees
Except when explicitly noted, all non-const member functions and associated functions taking
boost::bloom::filter by non-const reference provide the
basic exception guarantee,
whereas all const member functions and associated functions taking
boost::bloom::filter by const reference provide the
strong exception guarantee.
Except when explicitly noted, no operation throws an exception unless that exception
is thrown by the filter’s Hash or Allocator object (if any).
Types and Constants
static constexpr std::size_t stride;
Equal to Stride if that parameter was specified as distinct from zero.
Otherwise, equal to used-value-size<subfilter>.
static constexpr std::size_t bulk_insert_size;
Chunk size internally used in bulk insert operations.
static constexpr std::size_t bulk_may_contain_size;
Chunk size internally used in bulk may_contain
operations.
Constructors
Default Constructor
filter();
Constructs an empty filter using hasher() as the hash function and
allocator_type() as the allocator.
| Preconditions: |
|
| Postconditions: |
|
Capacity Constructor
explicit filter( size_type m, const hasher& h = hasher(), const allocator_type& al = allocator_type()); filter( size_type n, double fpr, const hasher& h = hasher(), const allocator_type& al = allocator_type());
Constructs an empty filter using copies of h and al as the hash function and allocator, respectively.
| Preconditions: |
|
| Postconditions: |
|
Iterator Range Constructor
template<typename InputIterator>
filter(
InputIterator first, InputIterator last,
size_type m, const hasher& h = hasher(),
const allocator_type& al = allocator_type());
template<typename InputIterator>
filter(
InputIterator first, InputIterator last,
size_type n, double fpr, const hasher& h = hasher(),
const allocator_type& al = allocator_type());
Constructs a filter using copies of h and al as the hash function and allocator, respectively,
and calls insert(first, last).
| Preconditions: |
|
| Postconditions: |
|
Copy Constructor
filter(const filter& x);
Constructs a filter using copies of x's internal array, x.hash_function()
and std::allocator_traits<Allocator>::select_on_container_copy_construction(x.get_allocator()).
| Postconditions: |
|
Move Constructor
filter(filter&& x);
Constructs a filter transferring x's internal array to *this and using
a hash function and allocator move-constructed from x's hash function
and allocator, respectively.
| Postconditions: |
|
Iterator Range Constructor with Allocator
template<typename InputIterator>
filter(
InputIterator first, InputIterator last,
size_type m, const allocator_type& al);
template<typename InputIterator>
filter(
InputIterator first, InputIterator last,
size_type n, double fpr, const allocator_type& al);
Allocator Constructor
explicit filter(const allocator_type& al);
Constructs an empty filter using hasher() as the hash function and
a copy of al as the allocator.
| Preconditions: |
|
| Postconditions: |
|
Copy Constructor with Allocator
filter(const filter& x, const allocator_type& al);
Constructs a filter using copies of x's internal array, x.hash_function()
and al.
| Postconditions: |
|
Move Constructor with Allocator
filter(filter&& x, const allocator_type& al);
Constructs a filter transferring x's internal array to *this if
al == x.get_allocator(), or using a copy of the array otherwise.
The hash function of the new filter is move-constructed from x's
hash function and the allocator is a copy of al.
| Postconditions: |
|
Initializer List Constructor
filter( std::initializer_list<value_type> il, size_type m, const hasher& h = hasher(), const allocator_type& al = allocator_type()); filter( std::initializer_list<value_type> il, size_type n, double fpr, const hasher& h = hasher(), const allocator_type& al = allocator_type());
Capacity Constructor with Allocator
filter(size_type m, const allocator_type& al); filter(size_type n, double fpr, const allocator_type& al);
Initializer List Constructor with Allocator
filter( std::initializer_list<value_type> il, size_type m, const allocator_type& al); filter( std::initializer_list<value_type> il, size_type n, double fpr, const allocator_type& al);
Destructor
~filter();
Deallocates the internal array and destructs the internal hash function and allocator.
Assignment
Copy Assignment
filter& operator=(const filter& x);
Let pocca be std::allocator_traits<Allocator>::propagate_on_container_copy_assignment::value.
If pocca, replaces the internal allocator al with a copy of x.get_allocator().
If capacity() != x.capacity() or pocca && al != x.get_allocator(), replaces the internal array
with a new one with capacity x.capacity().
Copies the values of x's internal array.
Replaces the internal hash function with a copy of x.hash_function().
| Preconditions: |
If |
| Postconditions: |
|
| Returns: |
|
| Exception Safety: |
Strong. |
Move Assignment
filter& operator=(filter&& x)
noexcept(
std::allocator_traits<Allocator>::is_always_equal::value ||
std::allocator_traits<Allocator>::propagate_on_container_move_assignment::value);
Let pocma be std::allocator_traits<Allocator>::propagate_on_container_move_assignment::value.
If pocma, replaces the internal allocator with a copy of x.get_allocator().
If get_allocator() == x.get_allocator(), transfers x's internal array to *this;
otherwise, replaces the internal array with a new one with capacity x.capacity()
and copies the values of x's internal array.
Replaces the internal hash function with a copy of x.hash_function().
| Preconditions: |
If |
| Postconditions: |
|
| Returns: |
|
| Exception Safety: |
Nothrow as indicated, otherwise strong. |
Initializer List Assignment
filter& operator=(std::initializer_list<value_type> il);
Clears the filter and inserts the values from il.
| Returns: |
|
Capacity
Capacity
size_type capacity() const noexcept;
| Postconditions: |
|
| Returns: |
The size in bits of the internal array. |
Capacity Estimation
static size_type capacity_for(size_type n, double fpr);
| Preconditions: |
|
| Postconditions: |
|
| Returns: |
An estimation of the capacity required by a |
FPR Estimation
static double fpr_for(size_type n, size_type m);
| Postconditions: |
|
| Returns: |
An estimation of the resulting false positive rate when
|
Data Access
Array
boost::span<unsigned char> array() noexcept; boost::span<const unsigned char> array() const noexcept;
| Postconditions: |
|
| Returns: |
A span over the internal array. |
Modifiers
Insert
void insert(const value_type& x); template<typename U> void insert(const U& x);
If capacity() != 0, sets to one k * subfilter::k (not necessarily distinct)
bits of the internal array deterministically selected from the value
hash_function()(x).
| Postconditions: |
|
| Exception Safety: |
Strong. |
| Notes: |
The second overload only participates in overload resolution if
|
Insert Iterator Range
template<typename InputIterator> void insert(InputIterator first, InputIterator last);
Equivalent to while(first != last) insert(*first++).
If InputIterator is a LegacyForwardIterator
(C++11 to C++17) or satisfies std::forward_iterator
(C++20 and later), the range [first, last) is processed in chunks
of size bulk_insert_size using internal
streamlining techniques to increase performance with respect to
elementwise insertion.
| Preconditions: |
|
Insert Initializer List
void insert(std::initializer_list<value_type> il);
Equivalent to insert(il.begin(), il.end()).
Swap
void swap(filter& x)
noexcept(std::allocator_traits<Allocator>::is_always_equal::value ||
std::allocator_traits<Allocator>::propagate_on_container_swap::value);
Let pocs be std::allocator_traits<Allocator>::propagate_on_container_swap::value.
Swaps the internal array and hash function with those of x.
If pocs, swaps the internal allocator with that of x.
Reset
void reset(size_type m = 0); void reset(size_type n, double fpr);
First overload: Replaces the internal array if the resulting capacity calculated from m is not
equal to capacity(), and clears the filter.
Second overload: Equivalent to reset(capacity_for(n, fpr)).
| Preconditions: |
|
| Postconditions: |
In general, |
| Exception Safety: |
If |
Combine with AND
filter& operator&=(const filter& x);
If capacity() != x.capacity(), throws a std::invalid_argument exception;
otherwise, changes the value of each bit in the internal array with the result of
doing a logical AND operation of that bit and the corresponding one in x.
| Preconditions: |
The |
| Returns: |
|
| Exception Safety: |
Strong. |
Combine with OR
filter& operator|=(const filter& x);
If capacity() != x.capacity(), throws an std::invalid_argument exception;
otherwise, changes the value of each bit in the internal array with the result of
doing a logical OR operation of that bit and the corresponding one in x.
| Preconditions: |
The |
| Returns: |
|
| Exception Safety: |
Strong. |
Observers
get_allocator
allocator_type get_allocator() const noexcept;
| Returns: |
A copy of the internal allocator. |
Lookup
may_contain
bool may_contain(const value_type& x) const; template<typename U> bool may_contain(const U& x) const;
| Returns: |
|
| Notes: |
The second overload only participates in overload resolution if
|
Bulk may_contain
template<typename ForwardIterator, typename F> void may_contain(ForwardIterator first, ForwardIterator last, F f) const;
Equivalent to for( ; first != last; ++first) f(*first, may_contain(*first)).
The range [first, last) is processed in chunks
of size bulk_may_contain_size using internal
streamlining techniques to increase performance with respect to
elementwise lookup.
| Preconditions: |
|
Comparison
operator==
template< typename T, std::size_t K, typename S, std::size_t B, typename H, typename A > bool operator==( const filter<T, K, S, B, H, A>& x, const filter<T, K, S, B, H, A>& y);
| Preconditions: |
The |
| Returns: |
|
operator!=
template< typename T, std::size_t K, typename S, std::size_t B, typename H, typename A > bool operator!=( const filter<T, K, S, B, H, A>& x, const filter<T, K, S, B, H, A>& y);
| Preconditions: |
The |
| Returns: |
|
Subfilters
A subfilter implements a specific algorithm for bit setting (insertion) and
bit checking (lookup) for boost::bloom::filter. Subfilters operate
on portions of the filter’s internal array called subarrays. The
exact width of these subarrays is statically dependent on the subfilter type.
The full interface of a conforming subfilter is not exposed publicly, hence users can’t provide their own subfilters and may only use those natively provided by the library. What follows is the publicly available interface.
Subfilter::k
| Result: |
A compile-time |
typename Subfilter::value_type
| Result: |
A cv-unqualified, TriviallyCopyable type to which the subfilter projects assigned subarrays. |
Subfilter::used_value_size
| Result: |
A compile-time |
| Postconditions: |
Greater than zero and not greater than |
| Notes: |
Optional. |
used-value-size
template<typename Subfilter> constexpr std::size_t used-value-size; // exposition only
used-value-size<Subfilter> is Subfilter::used_value_size if this nested
constant exists, or sizeof(Subfilter::value_type) otherwise.
The value is the effective size in bytes of the subarrays upon which a
given subfilter operates.
<boost/bloom/block.hpp>
namespace boost{
namespace bloom{
template<typename Block, std::size_t K>
struct block;
} // namespace bloom
} // namespace boost
Class Template block
boost::bloom::block — A subfilter over an integral type.
Synopsis
// #include <boost/bloom/block.hpp>
namespace boost{
namespace bloom{
template<typename Block, std::size_t K>
struct block
{
static constexpr std::size_t k = K;
using value_type = Block;
// the rest of the interface is not public
} // namespace bloom
} // namespace boost
Description
Template Parameters
|
An unsigned integral type or an array of 2 |
|
Number of bits set/checked per operation. Must be greater than zero. |
<boost/bloom/multiblock.hpp>
namespace boost{
namespace bloom{
template<typename Block, std::size_t K>
struct multiblock;
} // namespace bloom
} // namespace boost
Class Template multiblock
boost::bloom::multiblock — A subfilter over an array of an integral type.
Synopsis
// #include <boost/bloom/multiblock.hpp>
namespace boost{
namespace bloom{
template<typename Block, std::size_t K>
struct multiblock
{
static constexpr std::size_t k = K;
using value_type = Block[k];
// the rest of the interface is not public
} // namespace bloom
} // namespace boost
Description
Template Parameters
|
An unsigned integral type or an array of 2 |
|
Number of bits set/checked per operation. Must be greater than zero. |
Each of the K bits set/checked is located in a different element of the
Block[K] array.
<boost/bloom/fast_multiblock32.hpp>
namespace boost{
namespace bloom{
template<std::size_t K>
struct fast_multiblock32;
} // namespace bloom
} // namespace boost
Class Template fast_multiblock32
boost::bloom::fast_multiblock32 — A faster replacement of
multiblock<std::uint32_t, K>.
Synopsis
// #include <boost/bloom/fast_multiblock32.hpp>
namespace boost{
namespace bloom{
template<std::size_t K>
struct fast_multiblock32
{
static constexpr std::size_t k = K;
using value_type = implementation-defined;
// might not be present
static constexpr std::size_t used_value_size = implementation-defined;
// the rest of the interface is not public
} // namespace bloom
} // namespace boost
Description
Template Parameters
|
Number of bits set/checked per operation. Must be greater than zero. |
fast_multiblock32<K> is statistically equivalent to
multiblock<std::uint32_t, K>, but takes advantage
of selected SIMD technologies, when available at compile time, to perform faster.
Currently supported: AVX2, little-endian Neon, SSE2.
The non-SIMD case falls back to regular multiblock.
used-value-size<fast_multiblock32<K>> is
4 * K.
<boost/bloom/fast_multiblock64.hpp>
namespace boost{
namespace bloom{
template<std::size_t K>
struct fast_multiblock64;
} // namespace bloom
} // namespace boost
Class Template fast_multiblock64
boost::bloom::fast_multiblock64 — A faster replacement of
multiblock<std::uint64_t, K>.
Synopsis
// #include <boost/bloom/fast_multiblock64.hpp>
namespace boost{
namespace bloom{
template<std::size_t K>
struct fast_multiblock64
{
static constexpr std::size_t k = K;
using value_type = implementation-defined;
// might not be present
static constexpr std::size_t used_value_size = implementation-defined;
// the rest of the interface is not public
} // namespace bloom
} // namespace boost
Description
Template Parameters
|
Number of bits set/checked per operation. Must be greater than zero. |
fast_multiblock64<K> is statistically equivalent to
multiblock<std::uint64_t, K>, but takes advantage
of selected SIMD technologies, when available at compile time, to perform faster.
Currently supported: AVX2.
The non-SIMD case falls back to regular multiblock.
used-value-size<fast_multiblock64<K>> is
8 * K.
Future Work
A number of features asked by reviewers and users of Boost.Bloom are considered for inclusion into future versions of the library.
try_insert
To avoid inserting an already present element, we now have to do:
if(!f.may_contain(x)) f.insert(x);These two calls can be combined in a potentially faster, single operation:
bool res = f.try_insert(x); // returns true if x was not presentEstimation of number of elements inserted
For a classical Bloom filter, the number of elements actually inserted can be estimated from the number \(B\) of bits set to one in the array as
\(n\approx-\displaystyle\frac{m}{k}\ln\left(1-\displaystyle\frac{B}{m}\right),\)
which can be used for the implementation of a member function
estimated_size. As of this writing, we don’t know how to extend the
formula to the case of block and multiblock filters. Any help on this
problem is much appreciated.
Run-time specification of k
Currently, the number k of bits set per operation is configured at compile time.
A variation of (or extension to) boost::bloom::filter can be provided
where the value of k is specified at run-time, the tradeoff being that
its performance will be worse than the static case (preliminary experiments
show an increase in execution time of around 10-20%).
Appendix A: FPR Estimation
For a classical Bloom filter, the theoretical false positive rate, under some simplifying assumptions, is given by
\(\text{FPR}(n,m,k)=\left(1 - \left(1 - \displaystyle\frac{1}{m}\right)^{kn}\right)^k \approx \left(1 - e^{-kn/m}\right)^k\) for large \(m\),
where \(n\) is the number of elements inserted in the filter, \(m\) its capacity in bits and \(k\) the number of bits set per insertion (see a derivation of this formula). For a fixed inverse load factor \(c=m/n\), the expression reaches at
\(k_{\text{opt}}=c\cdot\ln2\)
its minimum value \(1/2^{k_{\text{opt}}} \approx 0.6185^{c}\). The optimum \(k\), which must be an integer, is either \(\lfloor k_{\text{opt}}\rfloor\) or \(\lceil k_{\text{opt}}\rceil\).
In the case of filter of the form boost::bloom::filter<T, K, block<Block, K'>>, we can extend
the approach from Putze et al.
to derive the (approximate but very precise) formula:
\(\text{FPR}_{\text{block}}(n,m,b,k,k')=\left(\displaystyle\sum_{i=0}^{\infty} \text{Pois}(i,nbk/m) \cdot \text{FPR}(i,b,k')\right)^{k},\)
where
\(\text{Pois}(i,\lambda)=\displaystyle\frac{\lambda^i e^{-\lambda}}{i!}\)
is the probability mass function of a Poisson distribution
with mean \(\lambda\), and \(b\) is the size of Block in bits. If we’re using multiblock<Block,K'>, we have
\(\text{FPR}_\text{multiblock}(n,m,b,k,k')=\left(\displaystyle\sum_{i=0}^{\infty} \text{Pois}(i,nbkk'/m) \cdot \text{FPR}(i,b,1)^{k'}\right)^{k}.\)
As we have commented before, in general
\(\text{FPR}_\text{block}(n,m,b,k,k') \geq \text{FPR}_\text{multiblock}(n,m,b,k,k') \geq \text{FPR}(n,m,kk'),\)
that is, block and multiblock filters have worse FPR than the classical filter for the same number of bits set per insertion, but they will be faster. We have the particular case
\(\text{FPR}_{\text{block}}(n,m,b,k,1)=\text{FPR}_{\text{multiblock}}(n,m,b,k,1)=\text{FPR}(n,m,k),\)
which follows simply from the observation that using {block|multiblock}<Block, 1> behaves exactly as
a classical Bloom filter.
We don’t know of any closed, simple formula for the FPR of block and multiblock filters when
Stride is not its "natural" size used-value-size<Subfilter>,
that is, when subfilter subarrays overlap.
We can use the following approximations (\(s\) = Stride in bits):
\(\text{FPR}_{\text{block}}(n,m,b,s,k,k')=\left(\displaystyle\sum_{i=0}^{\infty} \text{Pois}\left(i,\frac{n(2b-s)k}{m}\right) \cdot \text{FPR}(i,2b-s,k')\right)^{k},\)
\(\text{FPR}_\text{multiblock}(n,m,b,s,k,k')=\left(\displaystyle\sum_{i=0}^{\infty} \text{Pois}\left(i,\frac{n(2bk'-s)k}{m}\right) \cdot \text{FPR}\left(i,\frac{2bk'-s}{k'},1\right)^{k'}\right)^{k},\)
where the replacement of \(b\) with \(2b-s\) (or \(bk'\) with \(2bk'-s\) for multiblock filters) accounts for the fact that the window of hashing positions affecting a particular bit spreads due to overlapping. Note that the formulas reduce to the non-overlapping case when \(s\) takes its default value (\(b\) for block, \(bk'\) for multiblock). These approximations are acceptable for low values of \(k'\) but tend to underestimate the actual FPR as \(k'\) grows. In general, the use of overlapping improves (decreases) FPR by a factor ranging from 0.6 to 0.9 for typical filter configurations.
\(\text{FPR}_{\text{block}}(n,m,b,s,k,k')\) and \(\text{FPR}_\text{multiblock}(n,m,b,s,k,k')\)
are the formulas used by the implementation of
boost::filter::fpr_for.
Appendix B: Implementation Notes
Hash Mixing
This is the bit-mixing post-process we use to improve the statistical properties of the hash function when it doesn’t have the avalanching property:
\(m\leftarrow\text{mul}(h,C)\),
\(h'\leftarrow\text{high}(m)\text{ xor }\text{low}(m)\),
where \(\text{mul}\) denotes 128-bit multiplication of two 64-bit factors, \(\text{high}(m)\) and \(\text{low}(m)\) are the high and low 64-bit words of \(m\), respectively, \(C=\lfloor 2^{64}/\varphi \rfloor\) and \(\varphi\) is the golden ratio.
32-bit mode
Internally, we always use 64-bit hash values even if in 32-bit mode, where the user-provided hash function produces 32-bit outputs. To expand a 32-bit hash value to 64 bits, we use the same mixing procedure described above.
Dispensing with Multiple Hash Functions
Direct implementations of a Bloom filter with \(k\) bits per operation require \(k\) different and independent hash functions \(h_i(x)\), which incurs an important performance penalty, particularly if the objects are expensive to hash (e.g. strings). Kirsch and Mitzenmacher show how to relax this requirement down to two different hash functions \(h_1(x)\) and \(h_2(x)\) linearly combined as
\(g_i(x)=h_1(x)+ih_2(x).\)
Without formal justification, we have relaxed this even further to just one
initial hash value \(h_0=h_0(x)\), where new values
\(h_i\) are computed from \(h_{i-1}\)
by means of very cheap mixing schemes. In what follows
\(k\), \(k'\) are the homonym values
in a filter of the form boost::bloom::filter<T, K, {block|multiblock}<Block, K'>>,
\(b\) is sizeof(Block) * CHAR_BIT,
and \(r\) is the number of subarrays in the filter.
Subarray Location
To produce a location (i.e. a number \(p\) in \([0,r)\)) from \(h_{i-1}\), instead of the straightforward but costly procedure \(p\leftarrow h_{i-1}\bmod r\) we resort to Lemire’s fastrange technique:
\(m\leftarrow\text{mul}(h_{i-1},r),\)
\(p\leftarrow\lfloor m/2^{64} \rfloor=\text{high}(m).\)
To decorrelate \(p\) from further uses of the hash value, we produce \(h_{i}\) from \(h_{i-1}\) as
\(h_i\leftarrow c \cdot h_{i-1} \bmod 2^{64}=\text{low}(c \cdot h_{i-1}),\)
with \(c=\text{0xf1357aea2e62a9c5}\) (64-bit mode), \(c=\text{0xe817fb2d}\) (32-bit mode) obtained from Steele and Vigna. The transformation \(h_{i-1} \rightarrow h_i\) is a simple multiplicative congruential generator over \(2^{64}\). For this MCG to produce long cycles \(h_0\) must be odd, so the implementation adjusts \(h_0\) to \(h_0'= (h_0\text{ or }1)\), which renders the least significant bit of \(h_i\) unsuitable for pseudorandomization (it is always one).
Bit selection
Inside a subfilter, we must produce \(k'\) values from \(h_i\) in the range \([0,b)\) (the positions of the \(k'\) bits). We do this by successively taking \(\log_2b\) bits from \(h_i\) without utilizing the portion containing its least significant bit (which is always one as we have discussed). If we run out of bits (which happens when \(k'> 63/\log_2b\)), we produce a new hash value \(h_{i+1}\) from \(h_{i}\) using the mixing procedure already described.
SIMD algorithms
fast_multiblock32
When using AVX2, we select up to 8 bits at a time by creating
a __m256i of 32-bit values \((x_0,x_1,...,x_7)\)
where each \(x_i\) is constructed from
a different 5-bit portion of the hash value, and calculating from this
the __m256i \((2^{x_0},2^{x_1},...,2^{x_7})\)
with _mm256_sllv_epi32.
If more bits are needed, we generate a new hash value as
described before and repeat.
For little-endian Neon, the algorithm is similar but the computations
are carried out with two uint32x4_ts in parallel as Neon does not have
256-bit registers.
In the case of SSE2, we don’t have the 128-bit equivalent of
_mm256_sllv_epi32, so we use the following, mildly interesting
technique: a __m128i of the form
\(((x_0+127)\cdot 2^{23},(x_1+127)\cdot 2^{23},(x_2+127)\cdot 2^{23},(x_3+127)\cdot 2^{23}),\)
where each \(x_i\) is in \([0,32)\),
can be reinterpret_casted to (i.e., has the same binary representation as)
the __m128 (register of floats)
\((2^{x_0},2^{x_1},2^{x_2},2^{x_3}),\)
from which our desired __m128i of shifted 1s can be obtained
with _mm_cvttps_epi32.
fast_multiblock64
We only provide a SIMD implementation for AVX2 that relies on two
parallel __m256is for the generation of up
to 8 64-bit values with shifted 1s. For Neon and SSE2, emulation
through 4 128-bit registers proved slower than non-SIMD multiblock<uint64_t, K>.
Release Notes
Boost 1.90
-
Added bulk-mode insertion and lookup for increased performance.
-
Made lookup implementation branchless for
block,fast_multiblock32andfast_multiblock64, which results in some performance gains, particularly for mixed successful/unsuccessful queries.
Boost 1.89
-
Initial release.
Acknowledgements
Peter Dimov and Christian Mazakas reviewed significant portions of the code
and documentation during the development phase. Sam Darwin provided support
for CI setup and documentation building. Braden Ganetsky contributed the
GDB pretty-printer for boost::bloom::filter.
The Boost acceptance review took place between the 13th and 22nd of May, 2025. Big thanks to Arnaud Becheler for his expert managing. The following people participated in the review: Dmitry Arkhipov, David Bien, Claudio DeSouza, Peter Dimov, Vinnie Falco, Alexander Grund, Seth Heeren, Andrzej Krzemieński, Ivan Matek, Christian Mazakas, Rubén Pérez, Kostas Savvidis, Peter Turcan, Tomer Vromen. Many thanks to all of them for their very helpful feedback.
Copyright and License
Of this documentation:
-
Copyright © 2025 Joaquín M López Muñoz
Distributed under the Boost Software License, Version 1.0.